Named Entity Recognition (NER) is an essential part of Natural Language Processing. I am a Senior Data Scientist at Phase One Karma, and I raise this topic to outline a modified approach to evaluating NER systems’ work used by the team and me. At some stage of developing the legal tech product, our team faced a crisis, as none of the existing approaches was a perfect fit. In this case, we took a fresh look at the metrics and designed a specific algorithm.
The typical way
Evaluating the quality of ML-algorithms (called metrics) is an essential part of the product’s development process. There is no point in improving the algorithm before the methods of metrics calculation are set up.
There exist some proven solutions for NER. For instance, we break the text up into tokens ( word sequences, punctuation symbols, and other lexemes in our task). Next, we mark each token as follows:
| Tokens | I | live | at | Palo | Alto | . |
| Codes | O | O | O | B-LOC | I-LOC | O |
This is a so-called BIO (Begin-Inside-Outside) encoding. The O means that this token does not relate to any of the identified entities. B-LOC indicates the first “B” token in a sequence like “LOC” (location). I-LOC – is for the second and consequent tokens of the same sequence. The second part of the code will be altered for other entities. Examples of standard types often found in articles, scientific papers, and datasets are as follows: PER – person, MISC – different, ORG – organization.
These are the typical metrics for measuring the quality of NER systems:
- Precision
- Recall
- F1
Introducing some definitions before going into detail:
- TP – true positive, the number of elements defined correctly as belonging to a class.
- FP – false positive – the number of elements that the algorithm marked as wrongly belonging to a class.
- TN – true negative – elements that were defined correctly as not belonging to a class.
- FN – false negative – elements that the algorithm has wrongly marked as not belonging to a class.
FP & FN are also known as the first and second error type. There are many different memes on the web that reflect these errors, so take a look for better understanding. I’m leaving one of the good ones here:

Picture: Effect Size FAQs by Paul Ellis
They have different values in different cases, and we need to shift the balance in one direction or another (explained below).
Precision is the fraction of retrieved documents that are relevant to the query:
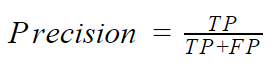
Recall is the fraction of the relevant documents that are successfully retrieved:
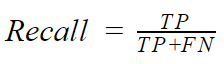
The mentioned metrics (in case there is no ideal classifier) pull the results in different directions. Usually, it is possible to “tweak” something in the classifier’s settings to make no mistakes when choosing elements. However, this also means that the classifier will be very careful — there won’t be plenty of marked elements that have to be marked and vice versa.
The harmonic mean of precision and recall is introduced to combine these two goals. Such a metric is called F1:
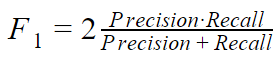
This value is closer to the poorest of the measures. This does not allow much improvement to one at the expense of deteriorating another.
We introduce measures with another β in the case when we have one error more important than the other:
![]()
Or in terms of first and second error type:
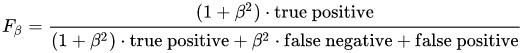
Thus, using the F2 metric, we make recall more important than precision (helpful when assessing those having an illness). On the contrary, if we use the F0.5 error-free option will be more critical. This option can be useful if further action involves more risk or cost in case of a wrong decision.
The standard version of metrics using BIO coding is implemented in the seqeval library. A minimal code can be viewed and run in Colab via the link:
https://colab.research.google.com/github/Loio-co/loio-metrics/blob/master/notebooks/seqeval.ipynb
What is wrong with the standard process
It seems like everything is concluded, why not stop here? Well, the standard approach didn’t work for one of our products.
One of the projects in Phase One Karma is LOIO, a legal tech product that offers the features of advanced styling, comparison, and AI-analysis for legal contracts. One of the crucial points of this project was to identify specific entities. In the beginning, we attempted to apply a standard approach and encountered particular challenges.
List of challenges:
- The process of calculating at the token level depends on the method of token splitting. Each parser does it a little differently.
- Some entity kinds like Spacings – spots that are left out to be filled, may even not contain tokens at all, in the common understanding.
- If there is a substantial difference in the length of the entities, there is also a bias towards the higher weight of longer ones. Here we are discussing the option of calculating coincidences at the token level (one matched token – +1 TP). Already mentioned library seqeval works differently — it scores complete matches of tokens sequences as one coincident.
These problems make you want to avoid using tokens; that’s why we continued to look for matches at the entities level. The matching of these entities is easier to determine by positions (in symbols) of their boundaries. Yet this leads to another problem:
- Loio has many long entities (spacing, definitions, addresses). It is tough to find their boundaries perfectly at once. So if you consider exact matches only, it is challenging to detect relatively small improvements or decline in quality before they lead to distinct border recognition. Such a quality function is inconvenient because it isn’t smooth. We must consider partial overlaps to make it smoother.
Another flexible option is BIO coding at the symbol level rather than a token level. This is a practical approach with a smooth quality function and the ability to work with spaces and other special characters. However, it still produces problems at the token level, such as:
- Great disbalance towards the higher score of long sequences.
- Spacings (yes, it is a very unusual entity kind) can have zero length. For example, when you type “Name:” followed by the end of a line, such scenarios are not considered by the symbol-as-token approach.
One approach to recording partial overlaps can be found in David S. Batista’s article “Named-Entity evaluation metrics based on entity-level.” In short, He suggests taking into account partial overlaps with coefficient ½. This is better than not considering it at all, but still, we go further.
Our approach
Input data
First of all, let’s see what the data is. The legal tech product Loio has a large number of entity kinds, and they can overlap, which is opposed to what most standard libraries expect. Let me give an example where one of the contract parties is marked, and some entities overlap with it (this is fake random data and any matches are coincident, https://www.fakenamegenerator.com/ used):
Party definition, Address, Location, Party term
This DIAGNOSTIC PLATFORM BENCHMARKING STUDY AND EVALUATION AGREEMENT (the “Agreement”) is made and entered into as of the last date of signature below (the “Effective Date”), by and between ProYard Services, a Delaware corporation having its principal place of business at 2140 Science Center Drive Burley, San Diego,CA, USA, ID 83318 (“PartyA”) and ZOEMENS AG, a German corporation having its principal place of business at Nuernbergerstrasse 89, 23626 Ratekau (“PartyB”).
There we observe a so-called “matryoshka.” Inside the party’s definition, there is the address of this party, which has a location in it. Usually, there is no point in showing data to the user in such a format. Nevertheless, it is necessary to find all geographical and administrative objects for further analysis.
Consequently, we further assume that counting each entity type performs separately, whereby border overlapping is not allowed for the same-type entities.
General points of our approach
We determine that the primary measures of Precision, Recall, F1 are calculated using the above formulas based on the values of TP, FP, FN. The only difference is how to calculate these same TP, FP, FN.
We calculate the number of correct matches as:
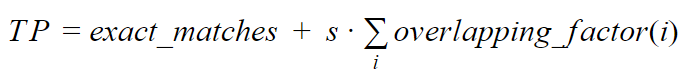
Where:
– exact_matches – number of exact matches (including matches with zero-length). Zero-length entities are checked only for exact matches.
– overlapping_factor(i) – intersection factor for partial overlap with index i. It is counted as the ratio of symbols in the intersection of the gold standard and found by the system, to the length of the largest of the entities involved in the intersection.
– s – support factor (stimulation) of partial matches. It should be in the range from 0 to 1.
As a result, we get a corrected TP that takes into account partial matches. To calculate FP, we subtract the TP from the total number of entities (correct and incorrect) found with the tested system.
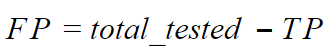
FN – is counted similarly, but we only use the number of entities in the gold standard sequence:
![]()
It is clear that when the stimulation factor equals zero, we get a standard scheme that takes into account only complete matches. The main distinction is that we are not dependent on tokens and work with entities that do not have tokens.
If the stimulation factor equals one, we don’t penalize a partial match in any way. We take into account only the intersection percentage. It is usual practice to wish to punish when the intersection is partial. Hence I often use the coefficient 0.75 in my projects.
Complex cases and steps of the algorithm
The algorithm explained above is still just a description of the principles. Now let’s consider complex cases that require a more complicated scheme to find partial intersections.
We often have partial matches of expected and found by the tested system of (actual) entities.
The most frequent type of partial matches in the gold standard and tested sequences (further we also use the terms expected and actual) is the following:
The gold standard (or Expected):
Some text with one long span
Tested (or Actual):
Some text with one long span
Some text with one long span
Some text with one long span
Here is an evident intersection of one character range in expected and one in the actual sequence.
There also can be other options, which need to be processed appropriately. Let’s assume we got such a markup:
The gold standard (Expected):
Some text with one long span
Tested (Actual):
Some text with one long span
It is unreasonable to take all partial matches into account, as we should stimulate the algorithm to find an identical number of entities (what is in gold standard)
The final procedure for calculating complete and incomplete coincidences is as follows:
- Let’s consider that the lists of expected and actual entities were passed on to the algorithm. The position of the first character sorts them, and there are no intersections.
- Сount the total matches.
- Кemove the entities with zero-length and full matches from both sequences and further consideration.
- Process the sorted entities of the actual sequence.
-
-
- We calculate an overlapping factor if there is a partial match, only from the opening part of the text as an entity in the expected sequence. We use it in the calculation of TP.
- We remove all the entities of the sequence affected by a partial match from further consideration.
-
Points 4.a/b. give us the required behavior. In this case, the account of a large number of small partial matches against the background of a long entity in the original sequence is not stimulated and vice versa.
An example
We follow the steps of the algorithm on an artificial example to make the algorithm simpler to understand. It is small but shows the features required. We go back to the recognition of the parties to the contract. Here is the correct definition of two parties (gold standard or expected):
This DIAGNOSTIC PLATFORM BENCHMARKING STUDY AND EVALUATION AGREEMENT (the “Agreement”) is made and entered into as of the last date of signature below (the “Effective Date”), by and between ProYard Services, a Delaware corporation having its principal place of business at 2140 Science Center Drive Burley, San Diego, CA, USA, ID 83318 (“PartyA”) and ZOEMENS AG, a German corporation having its principal place of business at Nuernbergerstrasse 89, 23626 Ratekau (“PartyB”).
There are two parties to the contract. Now let’s assume that some algorithm has produced the following markup of entities:
This DIAGNOSTIC PLATFORM BENCHMARKING STUDY AND EVALUATION AGREEMENT (the “Agreement”) is made and entered into as of the last date of signature below (the “Effective Date”), by and between ProYard Services, a Delaware corporation having its principal place of business at 2140 Science Center Drive Burley, San Diego, CA, USA, ID 83318 (“PartyA”) and ZOEMENS AG, a German corporation having its principal place of business at Nuernbergerstrasse 89, 23626 Ratekau (“PartyB”).
The algorithm here has highlighted 4 text fragments as the entity “party of the contract.” At the same time, only one of them has a perfect match with the expected one — the last fragment starting with “ZOEMENS AG.”
Let’s follow the steps of the algorithm.
The sorted entities:
| Expected | Actual |
| (1) This DIAGNOSTIC PLATFORM BENCHMARKING STUDY AND EVALUATION AGREEMENT (the “Agreement”) | |
| (1) ProYard Services, a Delaware corporation having its principal place of business at 2140 Science Center Drive Burley, San Diego, CA, USA, ID 83318 (“PartyA”) | (2) ProYard Services, a Delaware corporation having its principal place of business at 2140 Science Center Drive Burley, San Diego, CA, USA, |
| (3) 83318 (“PartyA”) | |
| (2) ZOEMENS AG, a German corporation having its principal place of business at Nuernbergerstrasse 89, 23626 Ratekau (“PartyB”) | (4) ZOEMENS AG, a German corporation having its principal place of business at Nuernbergerstrasse 89, 23626 Ratekau (“PartyB”) |
There is one total match between (2) and Actual (4). We remove these fragments from further consideration while remembering 1 as exact_matches.
Iterate over the rest of the Actual fragments. it is not crucial which sequence to go with to the algorithm, Actual or Expected. We only should agree to advance what sequence will be selected (Actual or Expected) to get reproducible results.
Actual (1) – does not intersect with anything in Expected. It is not considered further.
Actual (2) – partially intersected with Expected (1). The length of the intersection is 135 characters, the length of the longest entity from the intersection. Expected(1)=156 characters. Accordingly, the intersection factor = 135 / 156 = 0.8654. We get rid of Expected(1) from the further calculation.
Actual(3) – despite the fact that it overlaps with the Expected(1) fragment, we will not take this intersection into account since Expected(1) has already been considered in another partial intersection.
We calculate TP by our formula with a stimulation ratio of 0.75:
TP = exact_matches + s * sum(intersecting_factor) = 1 + 0.75 * 0.8654 = 1.6490
FP = total_actual – TP = 4 – 1.6490 = 2.351
FN = total_expected – TP = 2 – 1.6490 = 0.351
Now we can calculate the metrics of Precision, Recall, F1. Formulas are standard, but corrected for partial overlap TP, FP, FN:
Precision = TP / (TP + FP) = 1.649 / 4 = 0.4122
Recall = TP / (TP + FN) = 1.649 / 2 = 0.8245
F1 = 2 * (Precision * Recall) / (Precision + Recall) = 2 * (0.4122 * 0.8245) / (0.4122 + 0.8245) = 0.5496
Other metrics based on TP, FP, FN can be calculated in the same manner.
Original code sources
The described algorithm is implemented as an open-source library loio_metrics and published for public access https://github.com/Loio-co/loio-metrics.
An example of using the algorithm can be viewed on Google Colab: https://colab.research.google.com/github/Loio-co/loio-metrics/blob/master/notebooks/Loio_metrics_demo.ipynb.





